1
线上峰会
就在不久STM32的官方公众号发布了关于《STM32 全球线上峰会》的咨询消息。以《 ** 探索嵌入式AI的缤纷万花筒 **
》为题预计于12月13日举行。该次全球线上峰会的主题将围绕着STM32全新系列:STM32N6展开,甚至可以说是为STM32N6这款有着AI硬件加速和全面生态系统的单片机而开。

2
STM32N6
九月份参加了ST举办的全国巡回研讨会,在会中了解到了ST公司即将在今年十二月份推出其新产品——STM32N6系列,为赋能神经网络处理的MCU,这之后去了解STM32N6对其也非常的期待。
今年六月初,STM32关于N6系列的介绍。提到了其硬件性能。

除了常规的外设资源,其最引人注目的方面莫过于其板载NPU——一款算力高达600GOPS即每秒 六千亿次 (0.6TOPS)运算的神经网络处理单元。
这使得它特别适合在低功耗环境中加速 AI 计算(3TOPS/W的功率),能够胜任神经网络推理和机器学习任务。
并且板载RAM达到了4.2MB,极大的缓解了RAM不够存放模型文件的问题。
随着处理器算力的逐步提升,近年来边缘计算、MCU中的机器学习也被各大公司和博主提及的越来越多。今年这方面也作为了ST研讨会中着重介绍的一环,ST的专家着重介绍了他们在边缘AI上的布局以及CubeAI的使用展示,包括但不限于在STM32MP上运行Yolo神经网络获取人体关节等等。
我从创建公众号之初在尝试去了解和学习边缘计算和应用于MCU中的神经网络模型部署。
这一年来也陆陆续续使用了ST边缘AI生态中不同的工具来进行模型训练和AI,下面让我来聊一聊使用他们的感受。
3
NanoEdge AI
今年上半年开始接触到NanoEdge
AI,使用下来的感受是这是一款毫无疑问的,对STM32传感器数据做模型训练和部署的,非常简单甚至是跨时代的工具。在此之前,我从来没有想到过可以如此简单、快捷的在STM32中部署一些分类模型或者异常检测模型。
在传感器数据异常检测,分类模型中,利用Nanoedge非常方便的就可以实现那些本来需要门槛颇高的模型训练和部署。并且在如STM32F103C8T6等内存极为紧张的单片机中轻松部署。
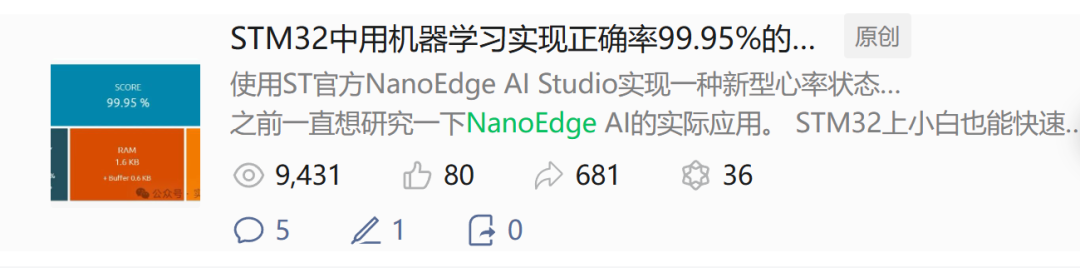
并且全流程实现下来,非常的简单,几乎没有半点卡顿。
可以说NanoEdge AI是让我在嵌入式神经网络领域中走出的第一步。
虽然NanoEdge AI在传感器数据的模型训练中非常方便,但是也有非常明显的弊端。
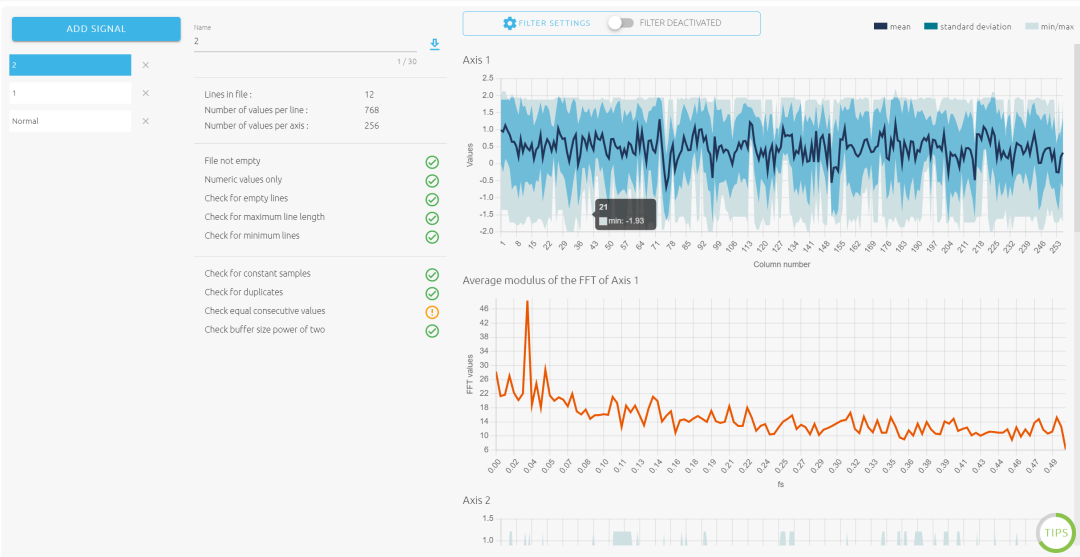
我们可以看到NanoEdge
AI将我们的传感器数据进行了傅里叶变换,似乎是利用频域信号进行的模型训练。这点在九月份的巡回研讨会中和ST的技术工程师交流过,得到了肯定的答案,因此在时变的传感器数据中,NanoEdge
AI可以充分的发挥其优势。而非时变信号如数据拟合,图像处理等则显得稍有劣势。同样的ST的工程师也向我介绍CubeAI来解决这些问题。
4
Cube AI
关于CubeAI去年就对其有所了解,但是关于机器学习方面的知识欠缺,所以导致自己迟迟不能应用。
不过随着自己不断学习,终于有能力自己训练模型的时候,之后迫不及待的用CubeAI在F407中部署了手写数字识别,手写Ascll码识别等Demo,并且取得了非常好的效果。

这两天也是用CubeAI实现了一种前馈神经网络的部署用来逼近非线性方程。
然而,当我使用CubeAI的时候,也不禁会为F4无法容大较大的神经网络模型和运算速度未来是否够用而烦恼。
而N6恰恰可以解决这些问题,基于M55内核CPU,4.2MB的大容量RAM,以及0.6TOPS的NPU算力,每一条都令我感到满意。
因此格外的期待ST的新产品问世(保佑直播抽奖抽个样板),也希望十二月份的ST线上峰会能为我们带来惊喜。
☆ * . ☆
. ∧_∧ ∩ * ☆
- ☆ ( ・∀・)/ .
. ⊂ ノ* ☆
☆ * (つ ノ .☆
(ノ